

Table des matières
PyTorch: Hybrid multi-node and multi-GPU parallelism (model and data)
The methodology presented on this page demonstrates how to adapt DataLoaders, models and the training loop to take advantage of multiple GPUs which could be distributed on multiple nodes.
Information will be drawn from the PyTorch pages PyTorch: Multi-GPU and multi-node data parallelism and PyTorch: Multi-GPU model parallelism. It would be useful to first consult these pages.
The orchestration of model distribution and data parallelism adds some supplementary steps to the previous documentation:
- Configuration of the Slurm environment
- Initialization of the code
- Adaptations to the model
The creation of DataLoaders is described on the page PyTorch: Multi-GPU and multi-node data parallelism. Model creation and implementation of the training loop can be copied from PyTorch: Multi-GPU model parallelism.
You will find the complete code here or in the DSDIR directory on Jean Zay, to be copied into your $WORK space:
$ cp $DSDIR/examples_IA/Torch_parallel/bench_DPP_transformer.py $WORK
Comment: This code is functional from the pytorch-gpu/py3/1.10.0 module.
The figure below shows an example of hybrid parallelism (4 GPUs with a copy of the model distributed on 2 GPUs):

Configuring the Slurm environment
Reminder:
- For data parallelization (Data Parallel Distribution variant), you must reserve as many tasks per node as there are GPUs:
torch.distributed.init_process_grouporchestrates the different tasks. - For model distribution, however, you must reserve only one task per model and as many GPUs as necessary for deploying a model instance (in this documentation, we parallelize one model on two GPUs).
You must be careful to create a number of tasks which corresponds to the number of trainings to be realized in parallel and not the number of GPUs.
If the trained model can fit into the memory of 2 GPUs with the desired batch size and we want to use three nodes, each node having 4 GPUs for the training, we must define the following Slurm options:
#SBATCH --gres=gpu:4 # reserves 4 GPUs per node #SBATCH --nodes=3 # reserves 3 nodes #SBATCH --ntasks-per-node=2 # creates 2 processes per node (therefore, 2 GPUs per process)
This corresponds to 6 processes turning in parallel, each having 2 dedicated GPUs.
In the case of two nodes (each having 8 GPUs), the configuration for 8 processes (each having 2 dedicated GPUs) will be:
#SBATCH --gres=gpu:8 # reserves 8 GPUs per node #SBATCH --nodes=2 # reserves 2 nodes #SBATCH --ntasks-per-node=4 # creates 4 processes per node (therefore, 2 GPUs per process)
Initializing the code
It is important to correctly define the GPUs to which the model inputs will be sent, as well as the GPU pairs on which the model will be distributed. For this, we import idr_torch script in the main code; this enables us to easily access the variables defined by Slurm (script proposed by IDRIS, PyTorch: Multi-GPU and multi-node data parallelism).
Recovering necessary variables
idr_torch gives us access to various information such as:
hostnames: A list of the names of the nodes involved in the job.size: Equivalent of SLURM_NTASKS (nodesin PyTorch jargon).rank: Equivalent of SLURM_PROCID which enables identification of a process.local_rank: Equivalent of SLURM_LOCALID which enables identification of a processs on a node and in our case assigns the GPUs to the right processes.cpus_per_task: Equivalent of SLURM_CPUS_PER_TASK which enables setting an adequate number of threads to read the data (num_workersdans la déclaration du data_loaders). Caution: The optimum value fornum_workersis rarelycpus_per_taskwhich is only an indication of the reasonable maximum value.
In addition, the following two variables are indispensable because they serve to create lists of GPUs for model distribution:
- NTASKS_PER_NODE: Slurm environment variable which is only accessible if using the
#SBATCH --ntasks-per-node=xor calculable with the variables provided byidr_torch. torch.cuda.device_count(): Number of GPU cards of the processes which are visible (that is, all the node cards!)
Implementation of the communication modes
import torch.distributed as dist # Initialize the communication for data distribution (DDP) dist.init_process_group(backend='nccl', init_method='env://', world_size=idr_torch.size, rank=idr_torch.rank) # Initialize the communication for Pipeline Parallelism dist.rpc.init_rpc(name="worker", rank=0, world_size=1, rpc_backend_options=dist.rpc.TensorPipeRpcBackendOptions( init_method="file://{}".format(tmpfile.name), # Specifying _transports and _channels is a workaround and we no longer # will have to specify _transports and _channels for PyTorch # versions >= 1.8.1 (Not True for Jean Zay) # With Jean Zay, _transports must be equal to ["shm", "uv"] and not ["ibv", "uv"] (as in pytorch doc) _transports=["shm", "uv"], _channels=["cuda_ipc", "cuda_basic"], ) )
Adaptations to the model
Defining the GPU groups per process
The objective is to assign a number of GPUs (corresponding to the number of parts of the sharded model) to each process and to give this number as parameter during model creation:
module_list = [] # The number of parts into which the model will be sharded nb_part = torch.cuda.device_count()//int(os.environ['SLURM_NTASKS_PER_NODE']) # The GPU I.D. number into which the first part of the model will go first_part = idr_torch.local_rank*nb_part # The GPU I.D. number into which the last part of the model will go last_part = first_part+nb_part-1 partition_len = max((args.nlayers / nb_part), 1) # The encoder will always be loaded by the first GPU with transformers tmp_list = [Encoder(args.ntokens, args.d_model, args.dropout).to(first_part)] # Add all the model transformer blocks and they will be loaded by the appropriate GPU for i in range(args.nlayers): transformer_block = Layer(args.d_model, args.n_head, args.d_hid, args.dropout) if i != 0 and i % (partition_len) == 0: module_list.append(nn.Sequential(*tmp_list)) tmp_list = [] device = int(i // (partition_len)) tmp_list.append(transformer_block.to(first_part+device)) # The model's head always goes into the last GPU with transformers. tmp_list.append(Decoder(args.d_model, args.d_hid).to(last_part)) module_list.append(nn.Sequential(*tmp_list)) # The Pipe checkpoint option should be configured on "never" so that it can work with DDP. # The model will, therefore, use much more memory than when we use the gradient checkpointing. model = Pipe(nn.Sequential(*module_list), chunks = args.chunks, checkpoint="never")
Encapsulating the model
After creating the distributed model, we add the following instruction to make it compatible with data parallelism:
ddp_mp_model = DistributedDataParallel(model)
This enables PyTorch to send the batch fractions to different model instances and to assure synchronization during the updating.
If we look at the profile of the DistributedDataParallel(...) function, we will find the following options:
device_ids= [...]output_device= i
Important: These variables must not be set in the case of a hybrid parallelism model.
Saving and loading the model
The saving of model parameters is only done on the master process:
if idr_torch.rank == 0 torch.save(model.module.state_dict(), name)
The addition of data parallelism to a model distributed on two (or more) GPUs adds an “indirection” to the parameter dictionary (model.module instead of model) which we can avoid in the saved file by directly recovering the dictionary from model.module rather than model (behavior by default).
The loading must be done by all the processes. Note that we have only tested the “static” configurations: loading of a bi-GPU model on a bi-GPU configuration. For more information, refer to the Saving and Loading Models tutorial.
if load_model: model.load_state_dict(torch.load(model_path)) ddp_mp_model = DistributedDataParallel(model)
Benchmark
A benchmark was created to compare the various parameters of Pipeline Parallelism and Data Parallelism (data distribution).
The tests were carried out on 4 and 8 GPUs, with different numbers of processes (ntasks). The number of processes ranges from 1 to 4 for tests on 4 GPUs and from 2 to 8 for tests on 8 GPUs. When there is only one process, only model parallelism is applied and when there are as many processes as GPUs, then only data parallelism is applied.
The model used is a transformer which is trained on the IMDB Review dataset with the goal of measuring the training performances (using a transformer for an uncomplicated task is not advised). Different batch sizes per GPU have also been tested, from 32 to 256, combined with different chunks, from 1 (naive model parallelism) to 32.
When a sample is missing, it is because the configuration is not possible (for example, when we want to do model parallelism but there are as many processes as GPUs). The results are as follows:
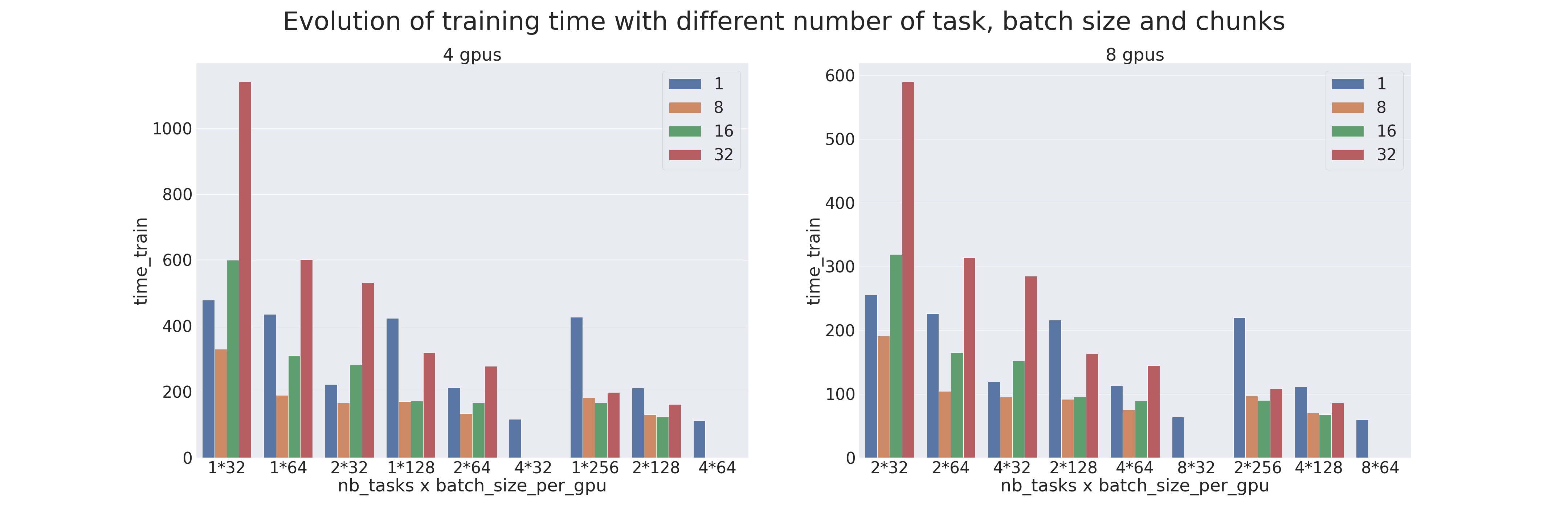
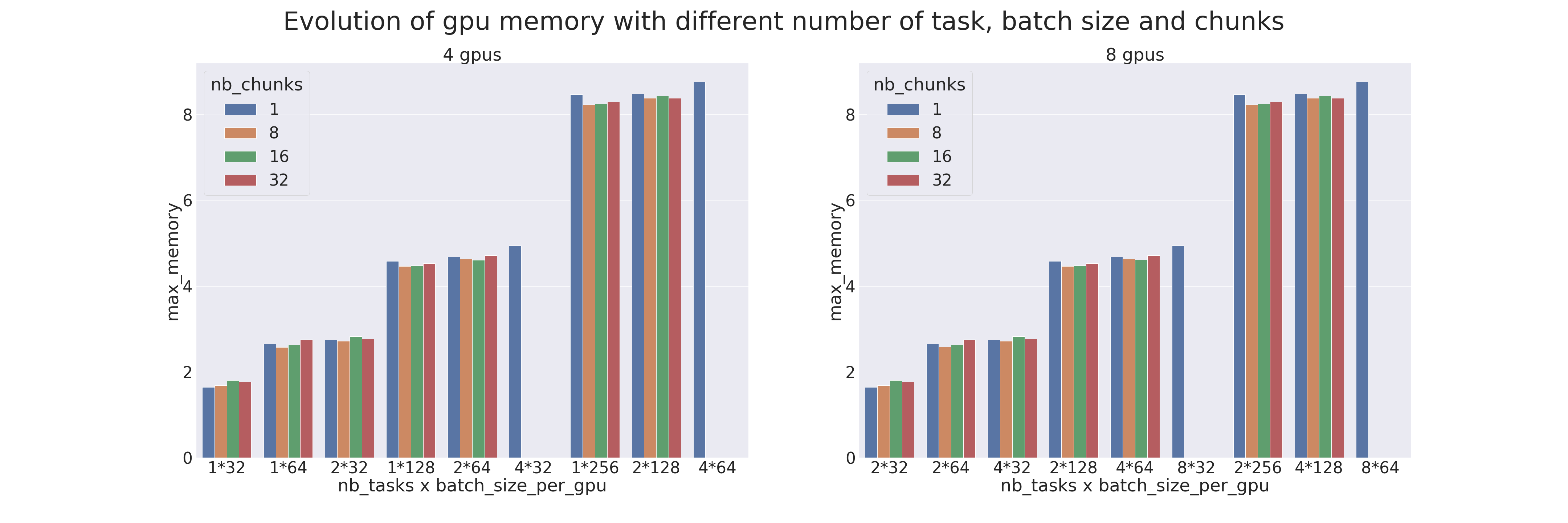
Complementary information
A few final comments:
- Optimization of a distributed code, model and data, is complex.
- Other techniques are available which enable limiting the GPU memory necessary for a model which can be easier to implement and just as effective; for example, Mixed-Precision (or AMP), Gradient Checkpointing and ZeRO optimization.