

Table des matières
Test de performance d'un entraînement Deep Learning avec et sans conteneurisation Singularity
But du benchmark
Les conteneurs sont de outils de plus en plus populaires pour leur facilité de déploiement sur tous types de machines. Cependant on peut se poser la question de leurs performances. Ce benchmark a pour but d’analyser les performances d'un algorithme d'apprentissage distribué sur GPU avec et sans conteneurisation.
Environnement de test
L'algorithme d'apprentissage utilisé est Mégatron, un transformeur développé par une équipe de NVIDIA. Il a été exécuté sur différends nombres de GPU pour voir la différence de temps d’exécution entre le code qui est lancé directement sur la machine et celui qui est exécuté via un conteneur.
Les tests sans conteneur ont été exécutés à l'aide de la commande Module. Le module utilisé est pytorch-gpu/py3/1.8.1.
Le script de soumission Slurm utilisé pour une exécution sans conteneur est le suivant (pour exécution sur 16 GPU sur des nœuds octo-gpu) :
#!/bin/sh #SBATCH --partition=gpu_p2 # utilise des nœuds ayant 24 CPUs et 8 GPUs #SBATCH --hint=nomultithread #SBATCH --time=01:00:00 #SBATCH --account=<my_project>@v100 # <my_project> est la valeur de IDRPROJ (echo $IDRPROJ) #SBATCH --job-name=megatron_16_GPU #SBATCH --nodes=2 # 2 nœuds réservés #SBATCH --ntasks=16 # 16 processus au total #SBATCH --cpus-per-task=3 # 3 cœurs par processus #SBATCH --ntasks-per-node=8 # 8 processus par nœud #SBATCH --gres=gpu:8 # 8 GPUs par nœud #SBATCH --output=./resultsAll/Megatron_%j_16_GPU.out #SBATCH --error=./resultsAll/Megatron_%j_16_GPU.err # go into the submission directory cd ${SLURM_SUBMIT_DIR} # cleans out modules loaded in interactive and inherited by default module purge module load pytorch-gpu/py3/1.8.1 ## launch script on every node set -x time srun python ./Megatron-LM/tasks/main.py --task IMDB --train-data /gpfswork/idris/sos/ssos024/Bench_Singularity/megatron_1B/imdb/dataset_train.csv --valid-data /gpfswork/idris/sos/ssos024/Bench_Singularity/megatron_1B/imdb/dataset_val.csv --tokenizer-type BertWordPieceLowerCase --vocab-file bert-large-uncased-vocab.txt --epochs 1 --tensor-model-parallel-size 1 --pipeline-model-parallel-size 1 --num-layers 24 --hidden-size 1024 --num-attention-heads 16 --micro-batch-size 8 --checkpoint-activations --lr 5.0e-5 --lr-decay-style linear --lr-warmup-fraction 0.065 --seq-length 512 --max-position-embeddings 512 --save-interval 500000 --save-interval 500 --log-interval 1 --eval-interval 1000 --eval-iters 50 --weight-decay 1.0e-1 --distributed-backend nccl --fp16
Les tests avec conteneurs on été réalisés avec l'outil de conteneurisation Singularity disponible sur Jean Zay via la commande module. Le conteneur utilisé est un docker Pytorch fourni par Nvidia.
On peut convertir une image docker en image Singularity avec la commande suivante, exécutée sur la partition prepost (avec ssh jean-zay-pp, car les frontales ont une limite en mémoire qui ne permet pas à la conversion d'aller à son terme) :
$ singularity build image_pytorch_singularity.sif docker:nvcr.io/nvidia/pytorch:21.03-py3
Le script de soumission Slurm utilisé pour une exécution avec conteneur est le suivant (pour exécution sur 16 GPU sur des nœuds octo-gpu) :
#!/bin/sh #SBATCH --partition=gpu_p2 # utilise des nœuds ayant 24 CPUs et 8 GPUs #SBATCH --hint=nomultithread #SBATCH --time=01:00:00 #SBATCH --account=<my_project>@v100 # <my_project> est la valeur de IDRPROJ (echo $IDRPROJ) #SBATCH --job-name=megatron_16_GPU_Singularity #SBATCH --nodes=2 # 2 nœuds réservés #SBATCH --ntasks=16 # 16 processus au total #SBATCH --cpus-per-task=3 # 3 cœurs par processus #SBATCH --ntasks-per-node=8 # 8 processus par nœud #SBATCH --gres=gpu:8 # 8 GPUs par nœud #SBATCH --output=./resultsAll/Megatron_%j_16_GPU_Sing.out #SBATCH --error=./resultsAll/Megatron_%j_16_GPU_Sing.err # go into the submission directory cd ${SLURM_SUBMIT_DIR} # cleans out modules loaded in interactive and inherited by default module purge module load singularity ## launch script on every node set -x time srun --mpi=pmix singularity exec --nv \ --bind .:$HOME,$JOBSCRATCH:$JOBSCRATCH $SINGULARITY_ALLOWED_DIR/MegaSingularity.sif \ python ./Megatron-LM/tasks/main.py --task IMDB --train-data ./imdb/dataset_train.csv --valid-data ./imdb/dataset_val.csv --tokenizer-type BertWordPieceLowerCase --vocab-file bert-large-uncased-vocab.txt --epochs 1 --tensor-model-parallel-size 1 --pipeline-model-parallel-size 1 --num-layers 24 --hidden-size 1024 --num-attention-heads 16 --micro-batch-size 8 --checkpoint-activations --lr 5.0e-5 --lr-decay-style linear --lr-warmup-fraction 0.065 --seq-length 512 --max-position-embeddings 512 --save-interval 500000 --save-interval 500 --log-interval 1 --eval-interval 1000 --eval-iters 50 --weight-decay 1.0e-1 --distributed-backend nccl --fp16
Résultats obtenus
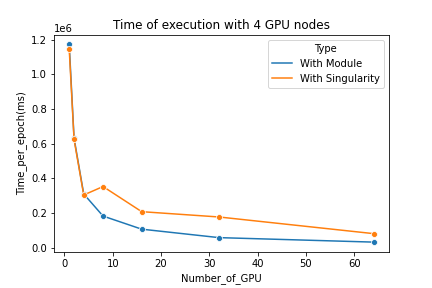

On peut voir que tant que le code est exécuté sur un seul nœud il n'y aucune perte de performance alors que lorsque plusieurs nœuds sont utilisés les exécutions via Singularity ont besoin de plus de temps que les exécutions sans conteneur.
Cette perte de performance reste relativement constante (autour de 100 000 ms) et n'est pas proportionnelle au nombre de nœuds utilisés.
On remarque que lorsque on utilise une image Singularity il est plus performant d'utiliser un seul nœud plutôt que deux car la perte de temps causée par le conteneur est plus élevée que le temps gagné par la parallélisation avec seulement deux nœuds.
Conclusion
On peut en conclure que l’exécution du code via un conteneur Singularity implique des pertes de performance notables sur les communications inter-nœud.
Il est important de noter que nos modules sont optimisés sur Jean-Zay, contrairement aux images de conteneurs, ce qui peut expliquer la différence de performance dans les interconnexions des nœuds GPU .