

Table des matières
Profilage de codes python
Nous présentons ici des techniques pour suivre spécifiquement l'évolution de la mémoire CPU et la durée des instructions lors de l'exécution d'un script Python.
Les 4 méthodes proposées sont faciles à mettre en œuvre et possèdent chacune des points forts. Notez qu'il n'y a, pour l'instant, pas d'outil open source de référence en Python pour faire ce genre de profilage.
Voici un récapitulatif des spécificités de chacune :
| type | impact vitesse | informations | |
|---|---|---|---|
| Scalene | mémoire, cpu | ++ | profilage complet ou par fonctions via décorateur, vue très complète sous forme de tableau (CPU, mémoire, GPU possible) |
| memory profiler | mémoire | +++ | profilage complet ou par fonctions via décorateur, vue agrégée |
| fil profiler | mémoire max | + | profilage mémoire générant un flame graph pour trouver l'instruction provoquant un pic d'allocation |
| manuellement | mémoire, cpu | . | deux codes Python qui permettent de ponctuellement observer une fonction (durée) ou une structure (mémoire) |
L'outil le plus complet est Scalene qui génère un fichier donnant des informations ligne par ligne du code ainsi profilé (cpu, mémoire, nombre d'appels). Il a aussi l'avantage de ne pas trop ralentir l'exécution (+33% constatés sur une expérimentation de traitement de données).
L'outil Memory profiler se distingue en proposant une vue graphique de l'occupation mémoire au cours du temps :
- ligne par ligne comme pour Scalene mais une fonction appelée plusieurs fois apparaît (avec son contenu) autant de fois qu'il y a d'appels ;
- l'affichage graphique permet de facilement voir les pics et les éventuelles fuites mémoire (il est normalement possible d'annoter les fonctions appelées sur ce graphe mais cela ne semble pas fonctionnel pour l'instant).
Ces deux outils nécessitent d'appeler le code via un exécutable (respectivement scalene et mprof) et/ou d'ajouter des lignes de code (un import et des décorateurs).
L'outil Fil profiler est le plus limité en terme de fonctionnalités mais il peut être intéressant si vous êtes habitué aux visualisations graphiques des appels de fonctions dans un code.
Mise en place
Si ces outils ne sont pas disponibles dans les modules qui vous intéressent :
- vous pouvez demander leurs installations à l'assistance () en précisant le module que vous utilisez
- ou vous pouvez les installer vous même en surchargeant un module existant (pytorch-gpu/py3/1.10.0 dans cet exemple) avec l'une des commandes pip suivantes :
module load pytorch-gpu/py3/1.10.0 pip install --upgrade --user --no-cache-dir memory_profiler pip install --upgrade --user --no-cache-dir filprofiler pip install --upgrade --user --no-cache-dir scalene
Certains de ces profilers sont activement développés, il peut donc être avantageux de les réinstaller avec l'option pip --upgrade même si des versions sont déjà disponibles dans les modules, pour pouvoir bénéficier des dernières fonctionnalités et corrections d'erreur.
Pour utiliser les exécutables de ces outils (quand ils existent), il est nécessaire de modifier la variable PATH avant leurs appels :
- Par défaut, les installations se font dans votre HOME donc utilisez la commande suivante
export PATH=$HOME/.local/bin:$PATH
- Mais si vous avez redéfini la variable PYTHONUSERBASE c'est cette variable qu'il faut utiliser
export PATH=$PYTHONUSERBASE/bin:$PATH
Conseils et remarques
- faites le profilage en réservant un nœud de calcul dynamiquement via
srunplutôt que via un job lancé parsbatch. Attention au délai d'attente pour obtenir les ressources de calcul qui varie en fonction de la charge de la machine ! - ne gardez pas le profilage actif si vous n'êtes plus en train d'expérimenter pour préserver votre quota d'heures de calcul !
- vérifiez les dernières versions des bibliothèques et les nouveautés.
- essayez de mettre les parties du code à profiler sous forme de fonctions ou de classes (pour l'usage de décorateur)
- il arrive que les profilers génèrent des fichiers core, n'oubliez pas de les effacer car ils peuvent être très volumineux
- attention, si vous avez un out of memory lors d'une session dynamique sur un nœud de calcul, vous n'en serez informé que lorsque vous quitterez cette session et non lorsque le programme exécuté échouera !
Scalene
Pour cet outil, le code est exécuté via la commande scalene plutôt que python :
- Par exemple, pour une sortie au format texte dans le terminal, utilisez la commande suivante :
$ scalene preprocess.py
- Et pour avoir une sortie au format html (le format txt est actif par défaut) dans un fichier, utilisez la commande suivante :
$ scalene --html --outfile profile.html preprocess.py
Pour ne profiler que certaines fonctions du code, il faut y ajouter le décorateur @profile (pas d'import nécessaire) :
@profile def preprocess_data(dataframe, verbose=False): ...
Ce qui donne ce type de sortie :
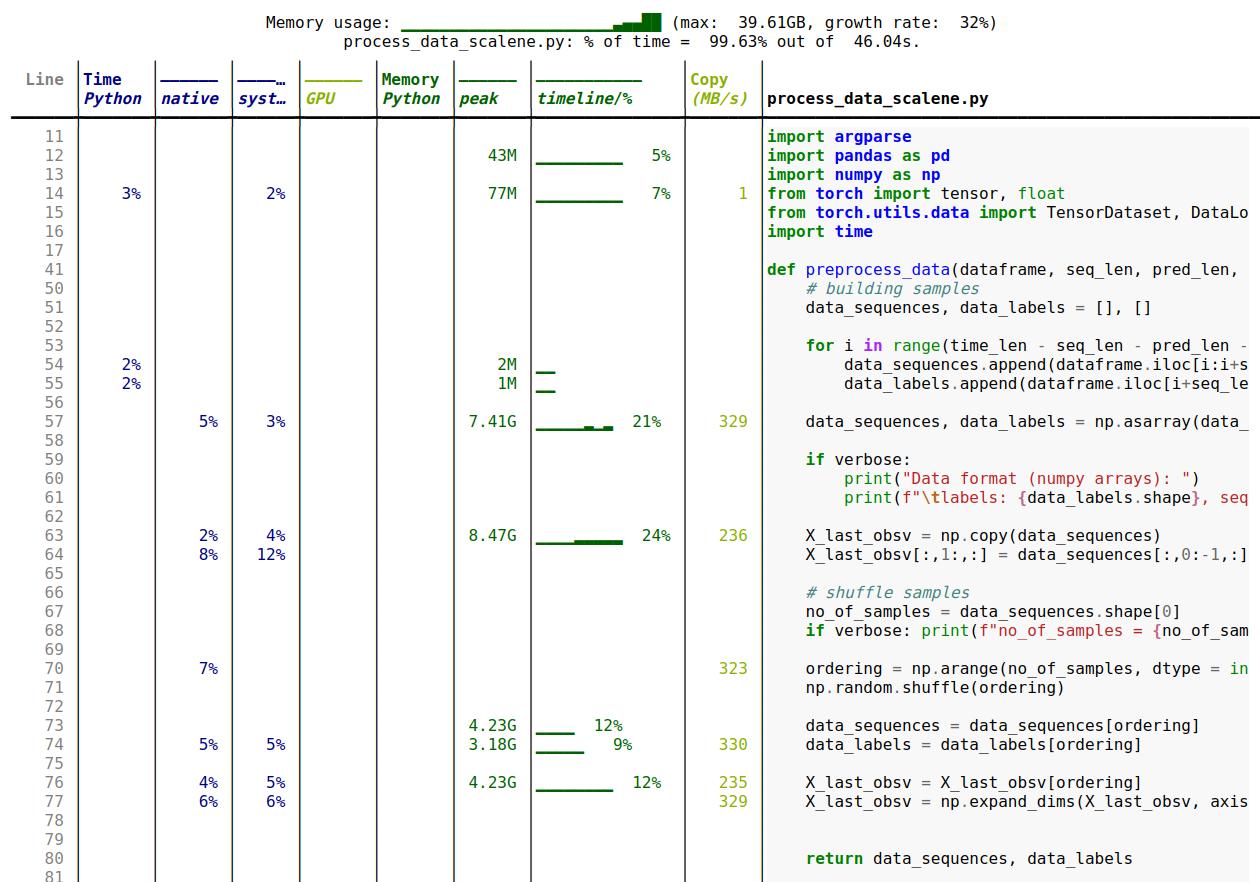
Memory profiler
Ce profiler propose deux modes de fonctionnement, selon que l'on souhaite avoir un graphe temporel de l'évolution de la mémoire et/ou une sortie au format texte de cette évolution.
Le mode de base produit un fichier texte contenant les évolutions de la mémoire allouée et nécessite d'ajouter les instructions suivantes dans les codes à profiler :
# Import necessaire from memory_profiler import profile # Fichier de sortie du profiler fp=open('memory_profiler.log','w+') # Profiling de la fonction avec sortie dans le fichier choisi @profile(stream=fp) def preprocess_data(dataframe, verbose=False): ...
Notez que le décorateur @profile(stream=fp) peut servir autant de fois qu'on le souhaite pour autant de fonctions différentes.
L'exécution du code se fait alors sans changement via la commande python.
Le fichier memory_profiler.log contiendra alors ce type d'information :
Filename: ./preprocess.py
Line # Mem usage Increment Occurrences Line Contents
=============================================================
37 303.9 MiB 303.9 MiB 1 @profile(stream=fp)
38 def preprocess_data(dataframe, seq_len, pred_len, verbose=False):
39 # iteratively build a numpy array from the dataframe using a
40 # sliding windows with dim seq_len + pred_len
41
42 303.9 MiB 0.0 MiB 1 time_len = dataframe.shape[0]
43
44 303.9 MiB 0.0 MiB 1 if verbose:
45 print(f"Preprocessing data with ...")
46
47 # building samples
48 303.9 MiB 0.0 MiB 1 data_sequences, data_labels = [], []
49
50 305.5 MiB 0.0 MiB 8680 for i in range(time_len - seq_len - pred_len - 1):
51 305.5 MiB 0.0 MiB 8679 data_sequences.append(dataframe.iloc[i:i+seq_len].values)
52 305.5 MiB 1.5 MiB 8679 data_labels.append(dataframe.iloc[i+seq_len:i+seq_len+pred_len].values)
53
54 5734.2 MiB 5428.7 MiB 1 data_sequences, data_labels = np.asarray(data_sequences), np.asarray(data_labels)
...
Le second mode de fonctionnement permet d'obtenir un graphe des évolutions de la mémoire. Le code doit être exécuté via la commande mprof :
mprof run preprocess.py
L'exécution génère alors un fichier dont le nom est du type mprofile_* que l'on peut interpréter pour en extraire un graphique via matplotlib.
Pour avoir le graphe du dernier profilage réalisé, il suffit de faire :
mprof plot
Si vous souhaitez visualiser un autre fichier, il vous suffit de d'ajouter son nom dans la ligne de commande.
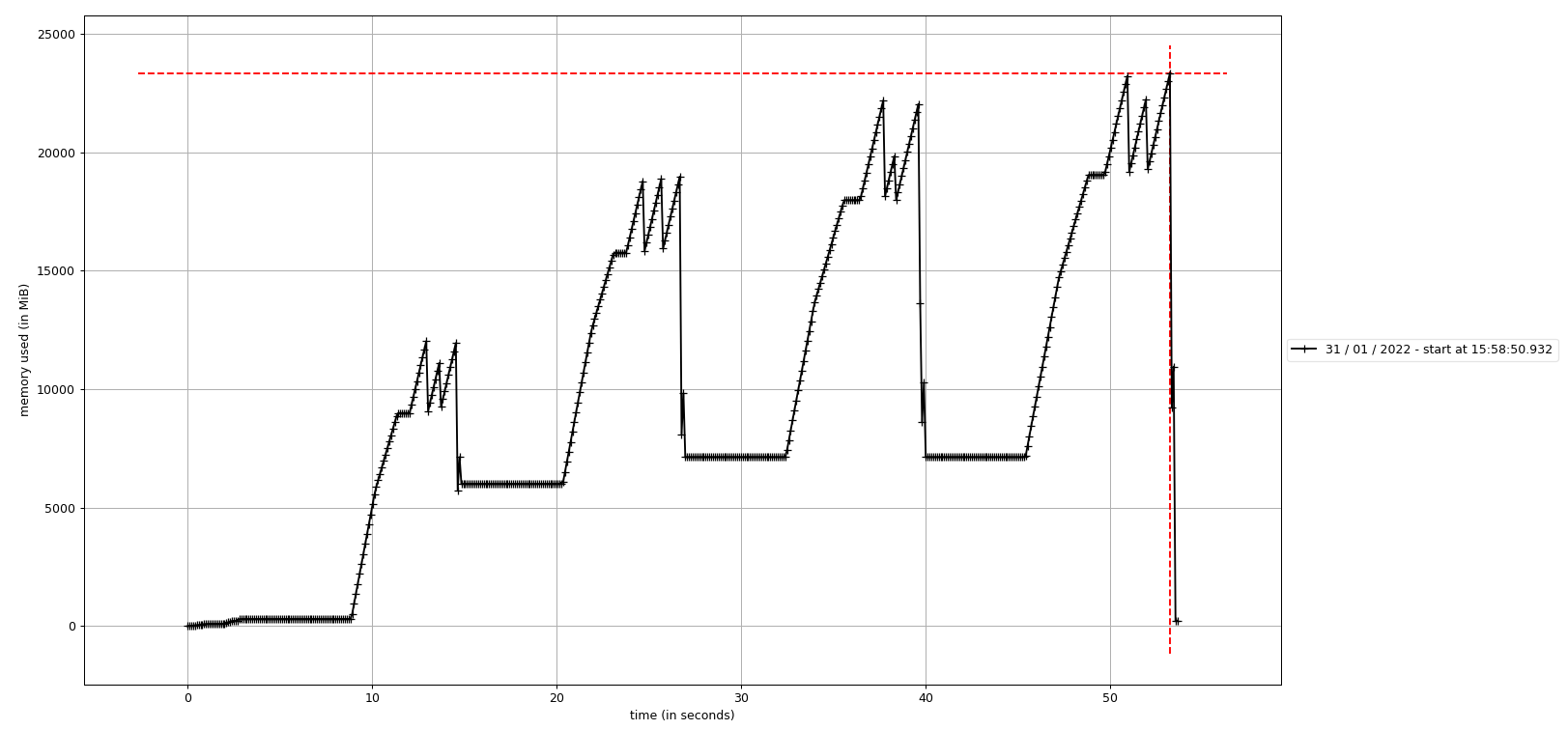
A noter que la génération du graphe nécessite l'accès à un environnement graphique (sur Jean Zay, ce sont les nœuds “visu”, voir Partitions Slurm CPU et Noeuds de visualisation), le plus simple étant d'utiliser cette fonctionnalité sur son ordinateur local.
L'outil Memory profiler a de nombreux modes, qu'il est possible de voir en lançant mprof sans argument, puis mprof <mode> -h pour les options relatives à un mode donné.
Remarque : la dernière version (0.60) de Memory Profiler n'implémente pas les fonctionnalités suivantes (qui sont pourtant décrites dans la documentation) :
- la possibilité de ne logger que les lignes avec un incrément de mémoire
- les graphes avec marquage temporel des sections passées dans des fonctions profilées
- l'usage de l'option flame pour générer le graphique avec un flame graph superposé
Fil Profiler
Ce profiler est la version open source d'un outil commercial. Il est assez limité mais en contrepartie son impact sur la durée d'exécution du programme est moindre.
Pour obtenir un flame graph (et donc l'endroit où se situe dans un code la portion la plus gourmande en mémoire), il faut lancer le code ainsi :
fil-profile run preprocess.py
Cela génère un répertoire contenant un fichier html et 2 images vectorielles (svg) contenant chacune un flame graph :

Pour profiler une partie du code, il suffit de modifier le code ainsi :
from filprofiler.api import profile data_sequences, data_labels = profile(lambda: preprocess_data(raw_dataframe), "fil-result")
et d'exécuter ensuite le code de cette manière (attention : fil-profiler python et non pas fil-profile run) :
fil-profile python preprocess.py -t on
Remarque : contrairement au décorateur utilisé par les autres profilers, cette manière de procéder permet de profiler une fonction en respectant des conditions (à implémenter soi-même dans le code via un if … else …), par exemple ne profiler que sur le rang master en cas de code multi-tâches.
Investigation manuelle et ponctuelle
C'est la méthode la moins intrusive pour explorer des parties de code, en particulier si vous soupçonnez où se situe un problème potentiel.
Ces codes pourront être rassemblés dans un fichier tools.py (à rendre accessible via $PYTHONPATH par exemple).
Information sur la durée d'exécution d'une fonction
il suffit de définir les fonctions suivantes :
- tools.py
import time from functools import wraps def convert_time(seconds): return time.strftime("%H:%M:%S", time.gmtime(seconds)) def timing(func): @wraps(func) def wrap(*args, **kw): start_time = time.time() result = func(*args, **kw) duration = time.time() - start_time print(f"________ Duration of {func.__name__}(): {convert_time(duration)} \t {duration} seconds") return result return wrap
On utilise alors cette fonction timing via un décorateur :
from tools import timing @timing def suspicious_function(): ...
La manière d'exécuter le code est inchangée.
Une information similaire à celle ci-dessous apparaîtra dans la sortie du programme (ou dans le fichier défini via la directive Slurm --output si lancement via slurm).
________ Duration of suspicious_function(): 00:00:18 18.34224474 seconds
Information sur la mémoire réservée
Cette méthode n'est pas forcément fiable, et peut sous estimer la réelle occupation mémoire (ce qui est aussi le cas des outils présentés plus haut). Cela peut aussi ne pas être adéquat selon la complexité de la structure de données que vous souhaitez évaluer (voir les handlers dans le code ci-joint).
Dans le même ordre d'idée que la fonction de timing, on va définir dans un fichier tools.py, les fonctions suivantes :
- tools.py
from sys import getsizeof, stderr from itertools import chain from collections import deque try: from reprlib import repr except ImportError: pass def convert_byte(num, suffix="B"): for unit in ["", "Ki", "Mi", "Gi", "Ti", "Pi", "Ei", "Zi"]: if abs(num) < 1024.0: return f"{num:3.1f}{unit}{suffix}" num /= 1024.0 return f"{num:.1f}Yi{suffix}" def total_size(object_name, o, handlers={}, verbose=False): """ Returns the approximate memory footprint an object and all of its contents. Automatically finds the contents of the following builtin containers and their subclasses: tuple, list, deque, dict, set and frozenset. To search other containers, add handlers to iterate over their contents: handlers = {SomeContainerClass: iter, OtherContainerClass: OtherContainerClass.get_elements} """ dict_handler = lambda d: chain.from_iterable(d.items()) all_handlers = {tuple: iter, list: iter, deque: iter, dict: dict_handler, set: iter, frozenset: iter, } all_handlers.update(handlers) # user handlers take precedence seen = set() # track which object id's have already been seen default_size = getsizeof(0) # estimate sizeof object without __sizeof__ def sizeof(o): if id(o) in seen: # do not double count the same object return 0 seen.add(id(o)) s = getsizeof(o, default_size) if verbose: print(f"________ Memory consumption of {object_name} ({type(o)}) {convert_byte(s)}") for typ, handler in all_handlers.items(): if isinstance(o, typ): s += sum(map(sizeof, handler(o))) break return s return sizeof(o)
Pour utiliser cette fonction :
from tools import total_size raw_dataframe = load_data() total_size("raw_dataframe", raw_dataframe, verbose= True)
Le résultat sera dans la sortie du programme (ou dans le fichier défini via “–output” si lancement via slurm) :
________ Memory consumption of raw_dataframe (<class 'pandas.core.frame.DataFrame'>) 68.5MiB