

Table des matières
Jean Zay : Utiliser DLProf avec PyTorch
DLProf est un outil de profilage fourni par Nvidia et dédié au Deep Learning. Il se base sur l'outil Nsight, également développé par Nvidia, qui est un profiler bas niveau. DLProf, par le biais de Nsight, recueille et enregistre les instructions lancées aux différents noyaux des GPU. L'application dlprofviewer sert d'interface entre les fichiers de logs de DLProf et le tableau de bord, dans lequel on pourra visualiser les différents rapports de l'outil.
Pour plus d'informations sur Nsight, vous pourrez voir la page de documentation suivante : Nsight Systems
Installation et Librairies
Sur Jean Zay, l'outil DLProf est installé sur les modules à partir de la version pytorch-gpu/py3/1.8.1.
Voici un exemple qui fonctionne :
module load pytorch-gpu/py3/1.9.0
Implémentation de DLProf
Pour faire fonctionner DLProf dans votre code vous devez rajouter quelques lignes de code.
Dans le script python
Avec nvidia-dlprof-pytorch-nvtx
Tout d'abord il faut charger le plugin et l'initialiser:
import nvidia_dlprof_pytorch_nvtx as dlprof dlprof.init()
Ensuite il faut lancer la boucle d’entraînement dans le contexte emit_nvtx de PyTorch. Ce contexte se chargera de récolter des valeurs pour le rapport Nsight.
with torch.autograd.profiler.emit_nvtx(): for epoch in range(2): for i, (texts, labels) in enumerate(train_loader): ...
Dans le script sbatch
De la même manière qu'avec Nsight, pour éviter de surcharger le dossier /tmp, il faut contraindre les fichiers temporaires à utiliser l'espace appelé $JOBSCRATCH.
Si on utilise un seul processus
Ainsi, vous pourrez utiliser DLprof dans votre script de lancement :
export TMPDIR=$JOBSCRATCH ln -s $JOBSCRATCH /tmp/nvidia srun dlprof --mode pytorch python script.py
Multi Processus
Si plusieurs processus sont utilisés (par exemple en multi-nœud ou en multi-GPU avec un processus par GPU), DLProf qui tourne sur chaque processus cherchera à écrire dans le même fichier, qui sera donc corrompu. Pour pallier ce problème, il faut spécifier un fichier de sortie différent pour chaque processus. De plus, il faut exporter les dossiers temporaires de DLprof dans chaque nœud et non pas seulement dans le nœud maître comme on le fait si on se contente de faire un export dans le script.
Un exemple de commande fonctionnelle (un peu long, mais qui a l'avantage de fonctionner dans tous les cas) serait :
srun bash -c 'export TMPDIR=${JOBSCRATCH}${SLURM_PROCID};\ mkdir -p ${TMPDIR}/tmp;\ ln -s ${TMPDIR}/tmp /tmp/nvidia;\ dlprof -m pytorch\ --output_path ./${SLURM_PROCID}\ --nsys_base_name nsys_${SLURM_PROCID}\ --profile_name dlprof_rank${SLURM_PROCID}\ python script.py'
Remarque : Vous obtiendrez alors un fichier de log par processus.
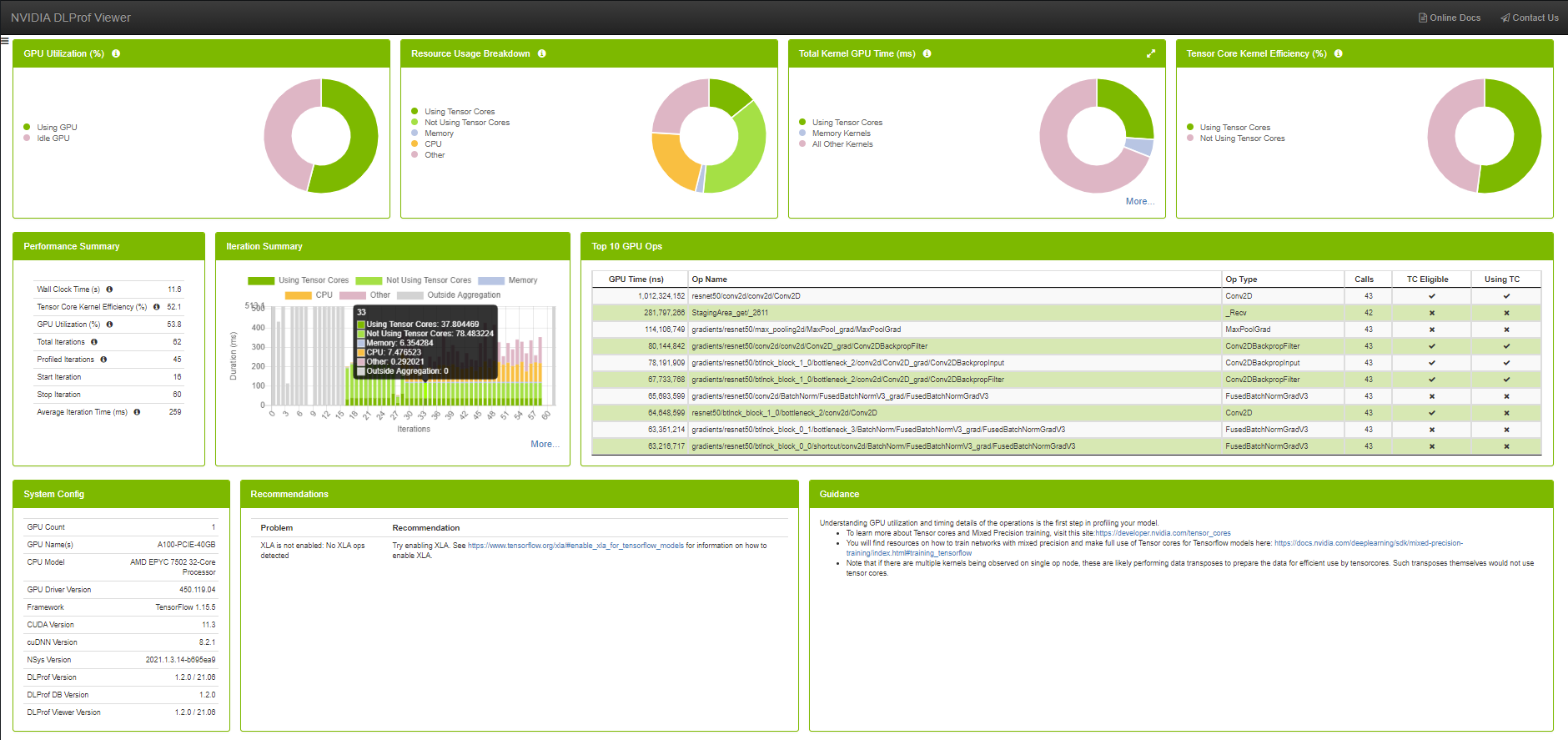
Visualisation avec DLProfviewer
Les fichiers de logs de DLProf (dlprof_dldb.sqlite) doivent être téléchargés sur votre machine personnelle afin d’être visualisés dans une installation locale de DLProfviewer.
Toutes les informations nécessaires pour l'utilisation et l'installation sont disponibles dans la documentation officielle de Nvidia : DLProfviewer user guide
Attention: Il faudra aligner la version de DLProfViewer au niveau de la version de pytorch utilisée (Voir la documentation).
Le tableau de bord de visualisation s'affiche simplement en ouvrant le bon fichier de log avec la commande:
dlprofviewer <dlprof_dldb>.sqlite
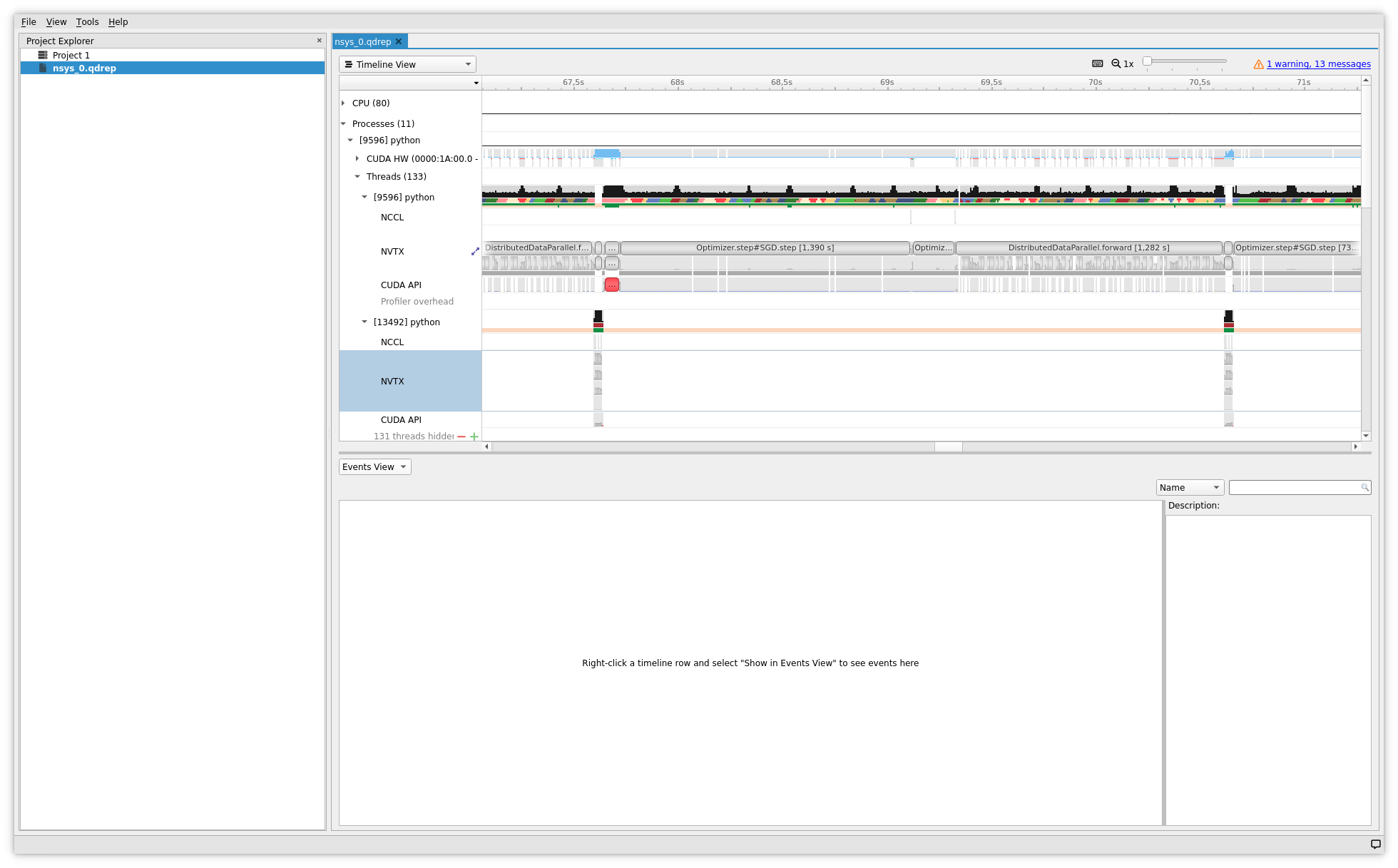
Visualisation de la Timeline avec Nsight
Pour visualiser les traces chronologiques, il faut ouvrir les rapports Nsight générés par dlprof.
Pour cela il faut:
- se connecter à Jean Zay avec l'option graphique (forwarding X11) :
ssh -X <login>@jean-zay.idris.fr
- charger un module comportant la bonne version de Nsight Systems, par exemple :
module load nvidia-nsight-systems/2021.2.1
- ouvrir le fichier de trace avec l'outil graphique de Nsight, par exemple :
nsys-ui nsys_0.qdrep
Bonne Utilisation du profiler
Augmentation du temps de calcul
Dans le cas où le profiler ralentirait drastiquement l'entraînement, créerait des out of memory, ou d'autres erreurs en raison de la surcharge d'opérations qu'il engendre, il est conseillé de réduire le nombre d'itérations (par exemple à 50, voire 10), avec les commandes --iter_start et --iter_stop (voir la documentation dlprof), ou en réduisant la taille du dataset. Le profiler n'est pas fait pour être lancé pendant un entraînement complet mais plutôt pour optimiser l'utilisation de la machine avant le véritable entraînement.