

Table des matières
Jean Zay : Outil de visualisation TensorBoard pour TensorFlow et PyTorch
Les algorithmes d'apprentissage automatique sont généralement coûteux en calcul. Il est donc essentiel de quantifier les performances de votre application de Machine Learning. L'outil graphique TensorBoard a été créé pour ce genre d'étude.
L'outil de visualisation TensorBoard est disponible sur Jean Zay via le JupyterHub de l'IDRIS.
La manière d'y accéder est décrite précisément dans la documentation dédiée : Jean Zay JupyterHub Documentation | JupyterLab Usage | Jupyter interface | Applications.
Attention : pour accéder à Tensorboard, il faut se placer dans un environnement dans lequel l'outil a été installé :
- si vous avez ouvert une instance JupyterLab, il faudra préalablement charger un module (tensorflow, pytorch, …) contenant TensorBoard comme indiqué dans Jean Zay JupyterHub Documentation | JupyterLab Usage | Jupyter interface | Environment modules.
- si vous avez ouvert directement une instance TensorBoard sur un noeud de calcul (Spawn server on SLURM node + Frontend = Tensorboard), l'outil est disponible sans autre action de votre part.
Les fonctionnalités TensorBoard
TensorBoard propose différents onglets de visualisation. Les principaux outils sont :
- Scalars affiche l'évolution du loss et des métriques à chaque époque par défaut (Il est possible de l'adapter pour suivre la vitesse d'entraînement, le taux d'apprentissage et d'autres valeurs scalaires.)
- Graphs aide à visualiser la structure de votre modèle
- Distributions et Histograms montrent la distribution des poids et des biais à chaque époque
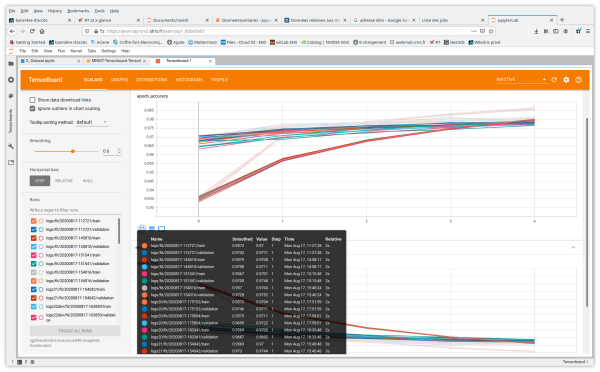
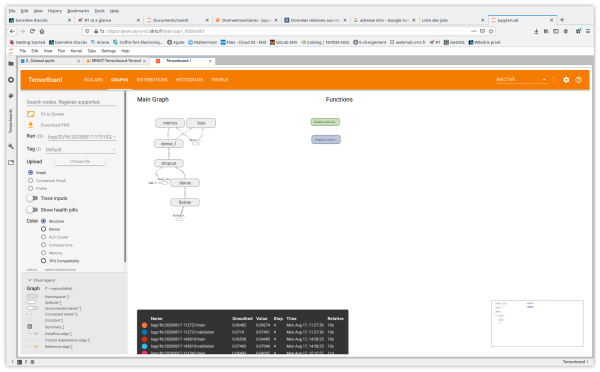
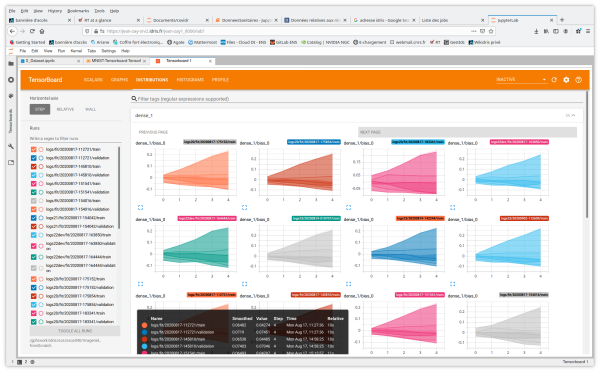
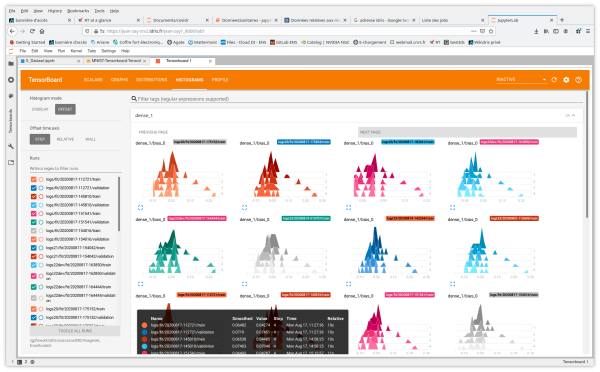
Vous avez également accès aux onglets et aux fonctionnalités Image Data, Hyperparameter Tuning, Embedding projector pour les applications de Natural Language Processing, What If Tool et Debugger V2.
Former un modèle avec les rappels TensorBoard
Pour bénéficier des fonctionnalités offertes par TensorBoard, il faut instrumenter votre code.
Instrumenter votre code TensorFlow
Pour générer des logs TensorBoard au format adéquat en sortie de votre application TensorFlow, il faut :
- créer un rappel TensorBoard pour capturer les métriques (ici
profile_batch = 0pour désactiver le profiler)
# Create a TensorBoard callback logs = "logs/" + datetime.now().strftime("%Y%m%d-%H%M%S") tboard_callback = tf.keras.callbacks.TensorBoard(log_dir = logs, histogram_freq = 1, profile_batch = 0)
- l'appeler pendant l'entraînement du modèle
# Train model model.fit(ds_train, epochs=2, validation_data=ds_test, callbacks = [tboard_callback])
Instrumenter votre code PyTorch
Pour générer des logs TensorBoard en sortie de votre application PyTorch, il faut
- définir un
writer
from torch.utils.tensorboard import SummaryWriter # default `log_dir` is "runs" - we'll be more specific here writer = SummaryWriter('runs/fashion_mnist_experiment_1')
- insérer des ordres de rappels TensorBoard adaptés aux résultats que vous souhaitez visualiser. Par exemple :
# TensorBoard callback for Scalars visualisation # here we report running loss value at each iteration i writer.add_scalar('training loss', running_loss / 1000, epoch * len(trainloader) + i)
# TensorBoard callback for ImageData visualisation writer.add_image('four_fashion_mnist_images', img_grid)
# TensorBoard callback for Graphs visualisation writer.add_graph(net, images)
# TensorBoard callback for Embedding Projector visualisation writer.add_embedding(features, metadata=class_labels, label_img=images.unsqueeze(1))
# TensorBoard callback for Weights/Bias histogramms writer.add_histogram('distribution_weight', np.concatenate([j[1].detach().cpu().numpy().flatten() for j in model.named_parameters() if 'bn' not in j[0] and 'weight' in j[0]]), epoch + 1) writer.add_histogram('distribution_bias', np.concatenate([j[1].detach().cpu().numpy().flatten() for j in model.named_parameters() if 'bn' not in j[0] and 'bias' in j[0]]), epoch + 1)
Documentation officielle
- Tensorboard : https://www.tensorflow.org/tensorboard/get_started?hl=en
- Pytorch avec Tensorboard : https://pytorch.org/tutorials/intermediate/tensorboard_tutorial.html