

Table des matières
Profilage d'applications PyTorch
Pytorch en fonction de sa version propose différents types de profiler intégré. La page présente décrit le nouveau Profiler construit sur TensorBoard et le précédent Profiler dit “natif” qui se visualise autrement.
Profilage Pytorch - TensorBoard
PyTorch intègre depuis la version 1.9.0, la fonctionnalité de profilage PyTorch Profiler comme plugin TensorBoard.
Instrumenter un code PyTorch pour le profilage TensorBoard
Dans le code PyTorch, il faut
- importer le profiler
from torch.profiler import profile, tensorboard_trace_handler, ProfilerActivity, schedule
- puis invoquer le profiler pendant l'exécution de la boucle d'apprentissage avec un
prof.step()à la fin de chaque itération.
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA], schedule=schedule(wait=1, warmup=1, active=12, repeat=1), on_trace_ready=tensorboard_trace_handler('./profiler'), #profile_memory=True ) as prof: for epoch in range(args.epochs): for i, (samples, labels) in enumerate(train_loader): ... prof.step() # Need to call this at the end of each step to notify profiler of steps' boundary.
Remarques :
- ProfilerActivity.CUDA : permet de récupérer les events CUDA (liés aux GPUs)
- profile_memory=True : permet de récupérer les traces de mémoire. A partir de
pytorch 1.10.0, cela est facile d'accès et ne rallentit pas l'acquisition des traces (contrairement aux vesions précédentes). - with_stack=True : permet de récupérer des informations brutes sur chaque opération mais augmente significativement la taille des traces.
- record_shapes=True : permet de récupérer le format des entrées.
- repeat=1 : pour répéter une seule fois le cycle de profilage (wait, warmup, active)
Visualisation du profilage avec TensorBoard
- Sur le jupyterHub de l'IDRIS, la visualisation des traces est possible en ouvrant TensorBoard selon la procédure décrite dans la page suivante.
- Ou alternativement, sur votre machine locale, l'installation du plugin TensorBoard permettant de visualiser les traces de profilage se fait comme suit :
pip install torch_tb_profiler
Il suffira ensuite de lancer normalement le TensorBoard avec la commande:
tensorboard --logdir <profiler log directory>
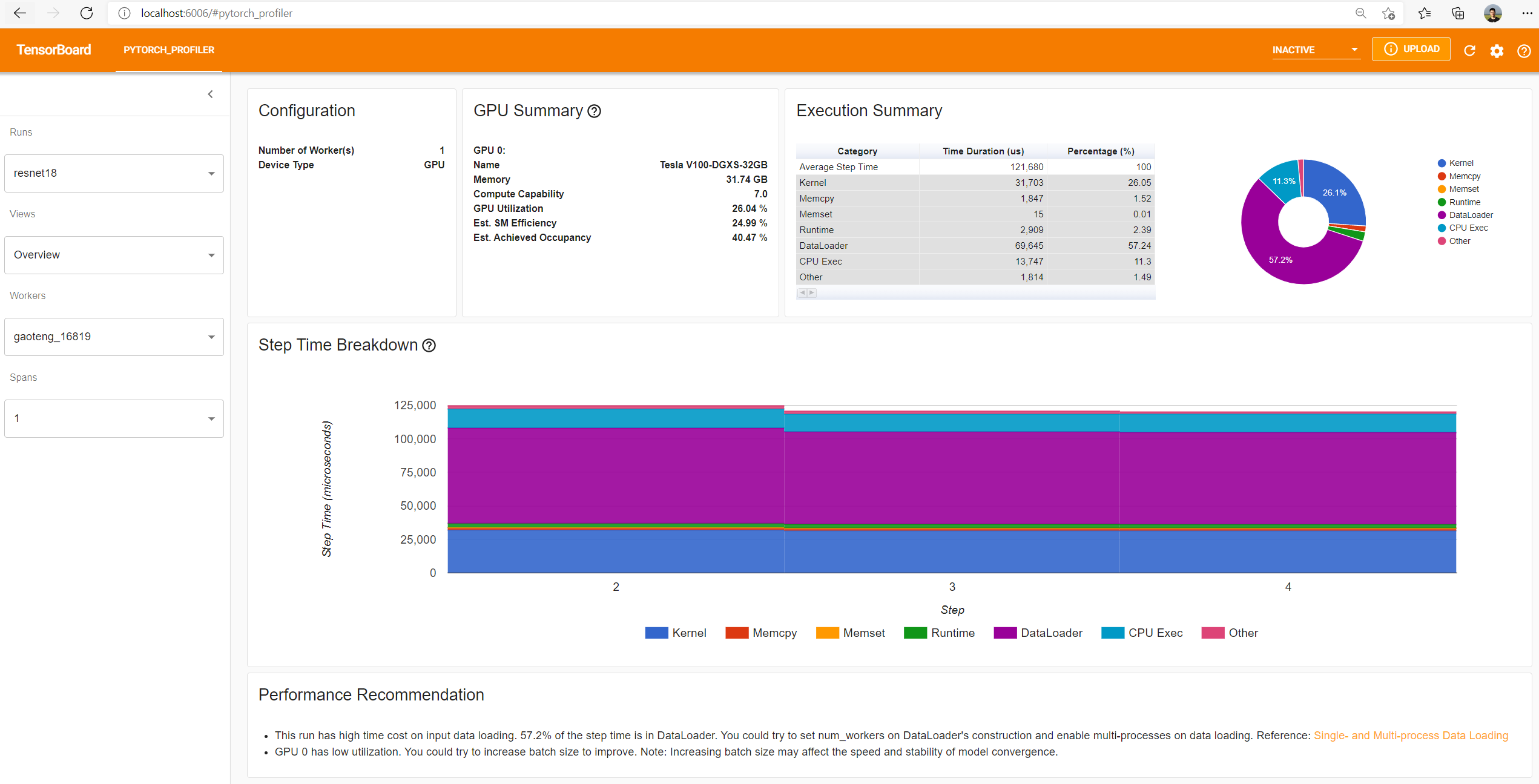
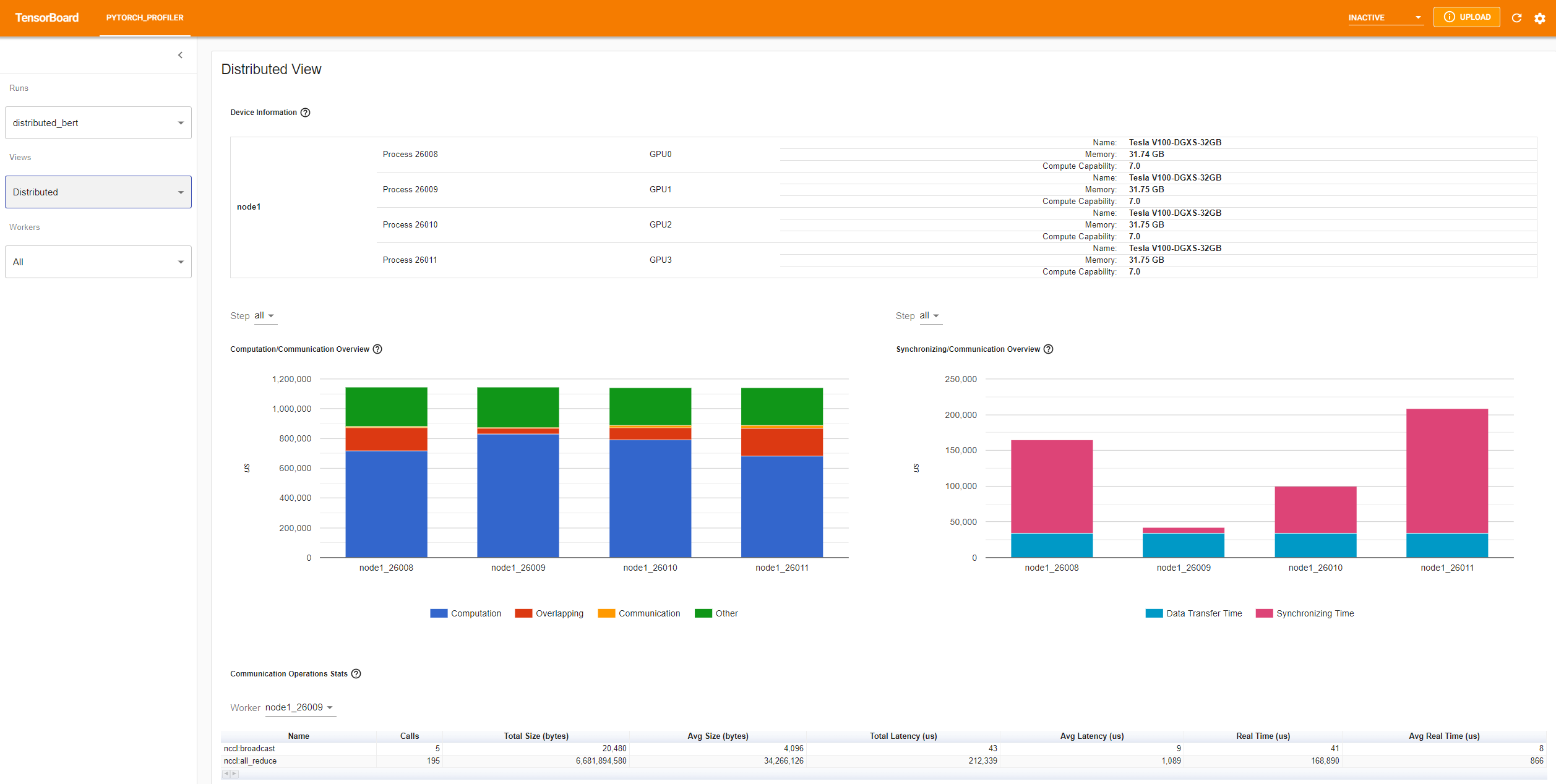
Dans l'onglet PYTORCH_PROFILER, vous trouverez différentes vues :
- Overview
- Operator view
- Kernel view
- Trace view
- Memory view, si l'option
profile_memory=Truea été instrumenté dans le code python. - Distributed view, si le code est distribué sur plusieurs GPU
Remarques : Depuis pytorch 1.10.0 des informations sur l'utilisation des Tensor Cores sont présentes sur Overview, Operator view et Kernel View.
Profilage Pytorch natif
Pour des raisons de simplicité ou par nécessité d'utiliser une version de Pytorch antérieure, vous pouvez aussi utiliser le profiler natif Pytorch.
Instrumenter un code PyTorch pour le profilage natif
Dans le code PyTorch, il faut:
- importer le profiler
from torch.profiler import profile, record_function, ProfilerActivity
- puis invoquer le profiler pendant l'exécution de la fonction d'apprentissage
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA], record_shapes=True) as prof: with record_function("training_function"): train()
Remarques :
- ProfilerActivity.CUDA : permet de récupérer les events CUDA (liés aux GPUs)
- with record_function(“$NAME”) permet de poser un décorateur (une balise associée à un nom) pour un bloc de fonctions. Il est donc aussi intéressant de poser des décorateurs dans la fonction d'apprentissage pour des ensembles de sous-fonctions. Par exemple:
def train(): for epoch in range(1, num_epochs+1): for i_step in range(1, total_step+1): # Obtain the batch. with record_function("load input batch"): images, captions = next(iter(data_loader)) ... with record_function("Training step"): ... loss = criterion(outputs.view(-1, vocab_size), captions.view(-1)) ...
- à partir de la version 1.6.0 de PyTorch, il est possible de profiler l'empreinte mémoire CPU et GPU en ajoutant le paramètre profile_memory=True sous profile.
Visualisation du profilage natif d'un code PyTorch
Visualisation d'un tableau de profilage
Une fois la fonction d'apprentissage exécutée, pour afficher les résultats du profile, il faut lancer la ligne :
print(prof.key_averages().table(sort_by="cpu_time", row_limit=10))
On obtient la liste de toutes les fonctions balisées automatiquement ou par nos soins (via les décorateurs), triée par ordre décroissant en temps CPU total. Par exemple :
|----------------------------------- --------------- --------------- ------------- -------------- Name Self CPU total CPU total CPU time avg Number of Calls |----------------------------------- --------------- --------------- ------------- -------------- training_function 1.341s 62.089s 62.089s 1 load input batch 57.357s 58.988s 14.747s 4 Training step 1.177s 1.212s 303.103ms 4 EmbeddingBackward 51.355us 3.706s 231.632ms 16 embedding_backward 30.284us 3.706s 231.628ms 16 embedding_dense_backward 3.706s 3.706s 231.627ms 16 move to GPU 5.967ms 546.398ms 136.599ms 4 stack 760.467ms 760.467ms 95.058ms 8 BroadcastBackward 4.698ms 70.370ms 8.796ms 8 ReduceAddCoalesced 22.915ms 37.673ms 4.709ms 8 |----------------------------------- --------------- --------------- --------------- ------------
La colonne Self CPU total correspond au temps passé dans la fonction elle-même, pas dans ses sous-fonctions.
La colonne Number of Calls contient le nombre de GPU utilisé par une fonction.
Ici, on voit que le temps de chargement des images (étape load input batch) est beaucoup plus important que celui de l'apprentissage du réseau de neurones (étape Training step). Le travail d'optimisation doit donc cibler le chargement des batchs.
Visualisation des traces de profilage avec l'outil de trace Chromium
Pour afficher un Trace Viewer équivalent à celui de TensorBoard, vous pouvez également générer un fichier de trace json avec la ligne suivante :
prof.export_chrome_trace("trace.json")
Ce fichier de trace est visualisable sur l'outil de trace du projet Chromium. À partir d'un navigateur CHROME (ou CHROMIUM), il faut lancer la commande suivante dans la barre URL:
about:tracing
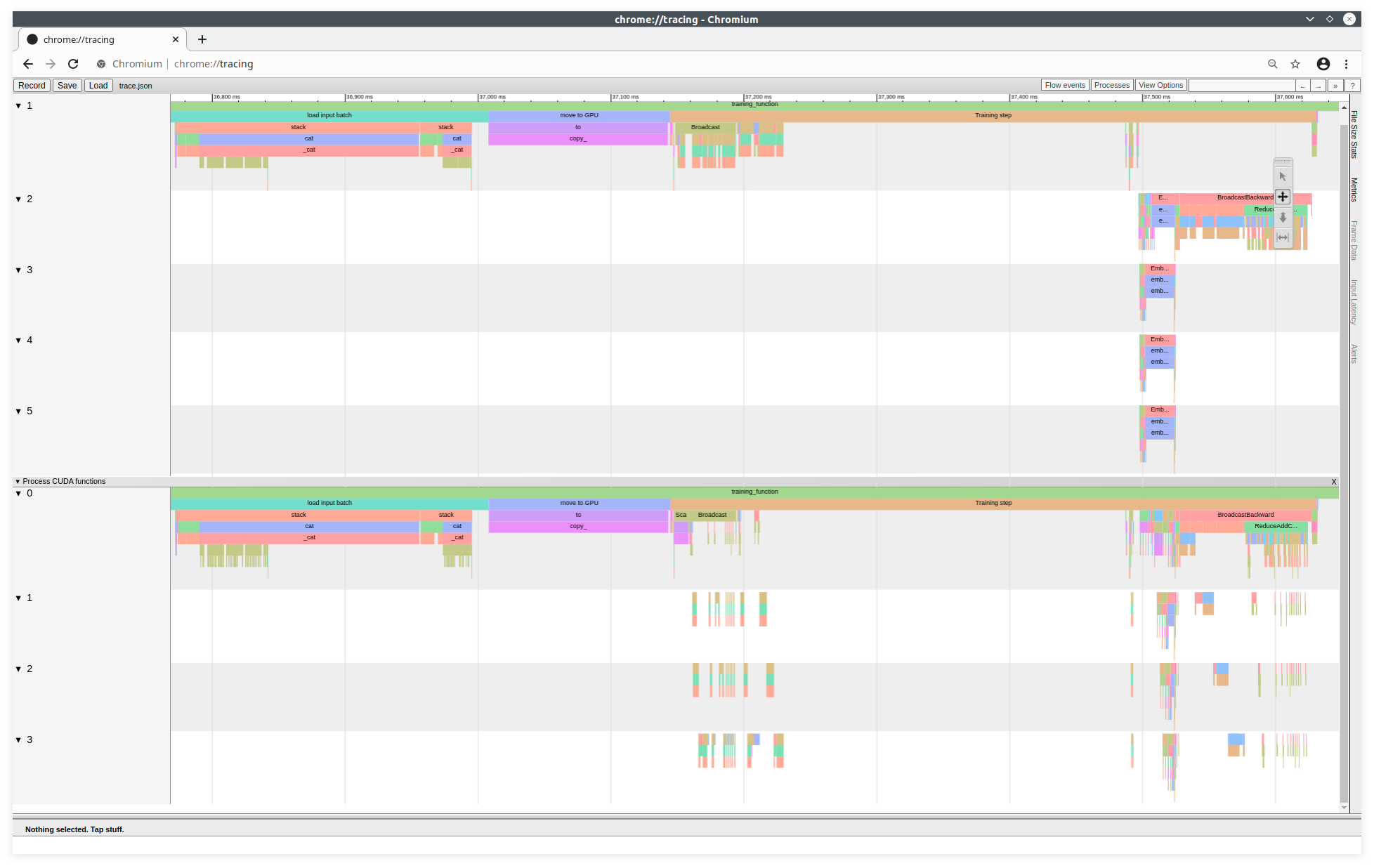
Ici, on voit distinctement l'utilisation des CPU et des GPU, comme avec TensorBoard. En haut, sont représentées les fonctions CPU et en bas, sont représentées les fonctions GPU. On a 5 tâches CPU et 4 tâches GPU. Chaque bloc de couleur représente une fonction ou une sous-fonction. Nous sommes à la fin d'un chargement.