

Table des matières
Profilage d'applications TensorFlow
TensorFlow intègre la fonctionnalité de profilage TensorFlow Profiler.
Le TensorFlow Profiler requiert des versions de TensorFlow et TensorBoard supérieures ou égales à 2.2. Sur Jean-Zay, il est disponible sous les versions 2.2.0 et supérieures de TensorFlow, en chargeant le module adéquat. Par exemple :
$ module load tensorflow-gpu/py3/2.2.0
Instrumenter un code TensorFlow pour le profilage
Pour générer des logs TensorBoard au format adéquat en sortie de votre application TensorFlow, il faut :
- créer un rappel TensorBoard pour capturer les métriques. Ici le profilage se fera entre les iterations 2 et 12 :
# Create a TensorBoard callback logs = "logs/" + datetime.now().strftime("%Y%m%d-%H%M%S") tboard_callback = tf.keras.callbacks.TensorBoard(log_dir = logs, histogram_freq = 1, profile_batch = (2,12))
- l'appeler pendant l'entraînement du modèle
# Train model model.fit(ds_train, epochs=2, validation_data=ds_test, callbacks = [tboard_callback])
Visualisation du profil d'un code TensorFlow
La visualisation des résultats de TensorFlow Profiler est possible via TensorBoard, dans l'onglet PROFILE. L'accès à TensorBoard sur Jean Zay est documenté ici. Vous pouvez aussi visualiser vos logs en les téléchargant sur votre machine locale.
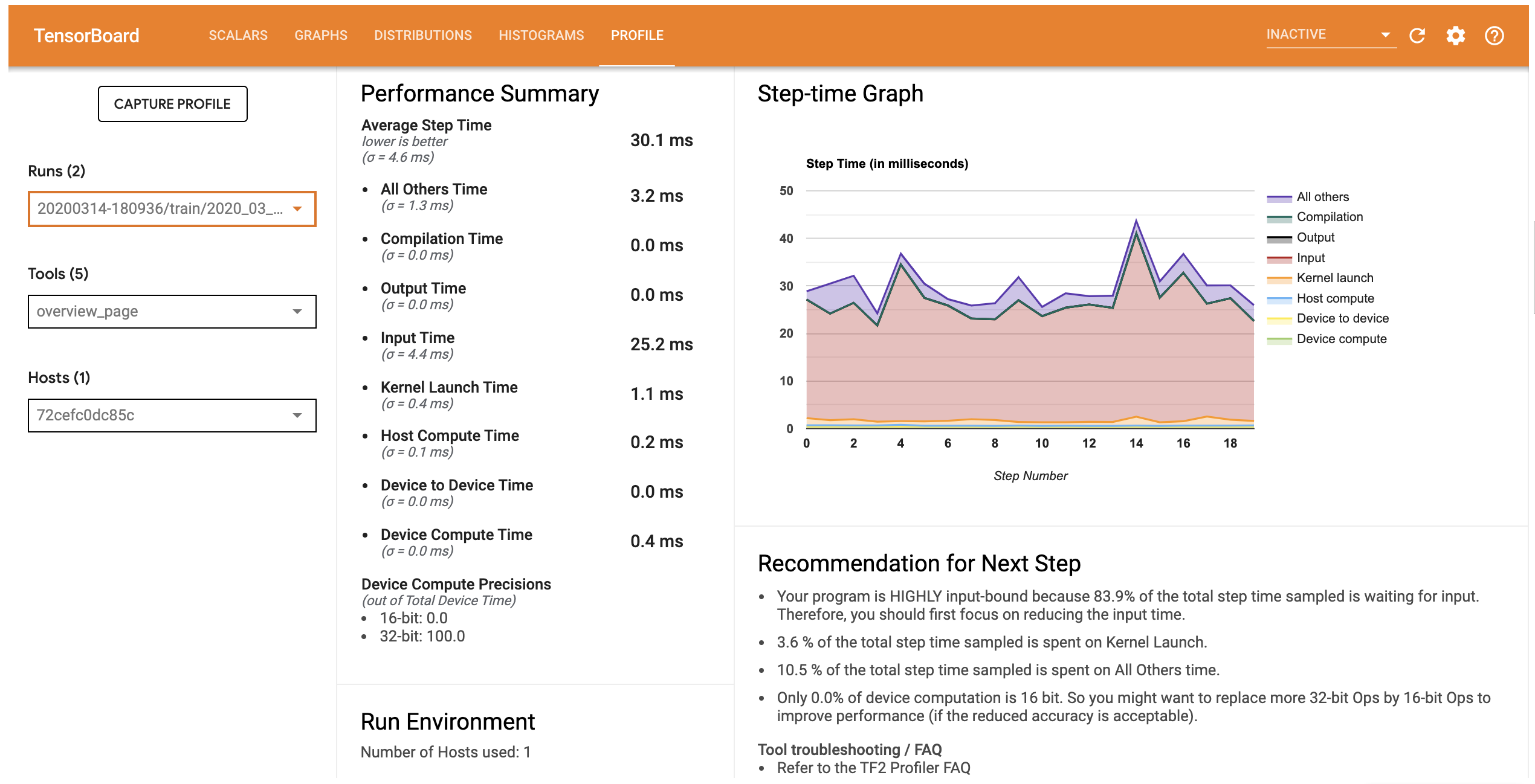
L'onglet PROFILE de TensorBoard s'ouvre sur l'Overview Page. Elle permet d'avoir un résumé de la performance en temps d'exécution des différentes étapes de calcul. Cela permet de savoir rapidement qui de l'apprentissage, du chargement des données ou du préprocessing des données, est le plus consommateur en temps d'exécution.
Puis la page Trace Viewer permet d'avoir une vue plus détaillée de la séquence d'exécutions, en distinguant les opérations exécutées sur GPU et sur CPU. Par exemple :
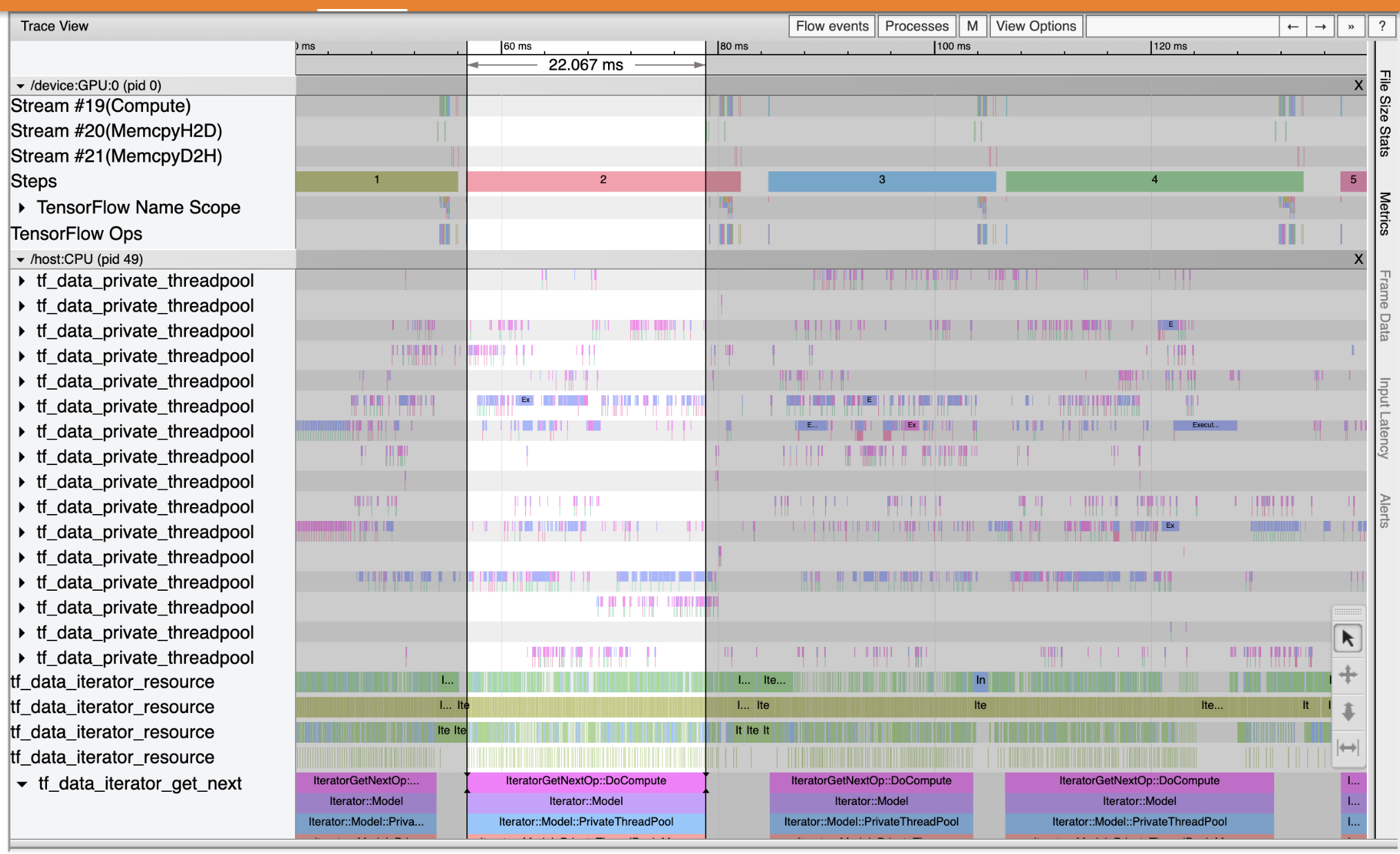
Dans cet exemple, on voit que le GPU (en haut) est peu utilisé par rapport au CPU (en bas) la plupart du temps. Les blocs de couleurs montrent que le GPU est utilisé seulement à la fin des steps, alors que le CPU est utilisé régulièrement sur certain threads. Une optimisation est certainement possible en répartissant mieux le travail entre GPU et CPU.
Documentations officielles
- Profile sur Tensorboard avec Tensorflow: https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras